Previous Article: DCGAN - (2) Architecture
이번 글에서는 DCGAN의 학습과정을 다뤄보자. 지금까지 그래왔듯이 pytorch구현을 위한 기술적인 부분은 미뤄두고, 개념만 다뤄볼 것이다.
기본적으로 Stochastic Gradient Descent(SGD)방법을 기반으로 하는 Adam Optimizer를 사용한다. SGD방법은 일반적인 Gradient Descent 방법과는 다르게 모든 데이터의 loss 값을 이용하지 않고 미리 정해둔 mini-batch 크기만큼 랜덤하게 추출한 데이터만을 가지고 진행하는 방법이다. 이렇게 확률적으로 진행되기 때문에 Stochastic이라는 명칭이 붙었다. Adam Optimizer에 대한 자세한 내용은 논문을 좀 더 공부한 후 적어보도록 하겠다.
I. Initialization
각 layer의 초기 weight들은 identically independent하게
II. Train Discriminator
Discriminator는 주어진 image를 정확히 예측하는 것이 목표이다. 즉,
mini-batch 크기만큼의 real 학습 데이터를 Discriminator에 넣어 loss
값을 구하고, backward로 Discriminator의 gradient를 구한다. mini-batch 크기만큼의 fake 데이터를 현재 Generator에서 생성하고, 이를 Discriminator에 넣어 loss
값을 구한다. 이후 마찬가지로 backward로 Discriminator의 gradient를 구한다. 1과 2에 의해 구해진 각 weight들에 대한 gradient의 평균을 가지고 Adam Optimizer를 통해 Discriminator의 parameter를 update한다.
III. Train Generator
Generator는 진짜같은 fake image를 만드는 것이 목표이기에
Discriminator 학습 시에 생성했던 fake images를 현재의 Discriminator에 넣어 loss
룰 구하고, backward로 Generator의 gradient를 구한다. 구한 gradient를 가지고 Adam Optimizer를 통해 Generator의 parameter를 update한다.
아래 그림은 pytorch에서 celeb-A데이터에 대하여 위와 같은 방법으로 학습시켰을 때의 Loss값의 변화를 나타낸 그래프이다.
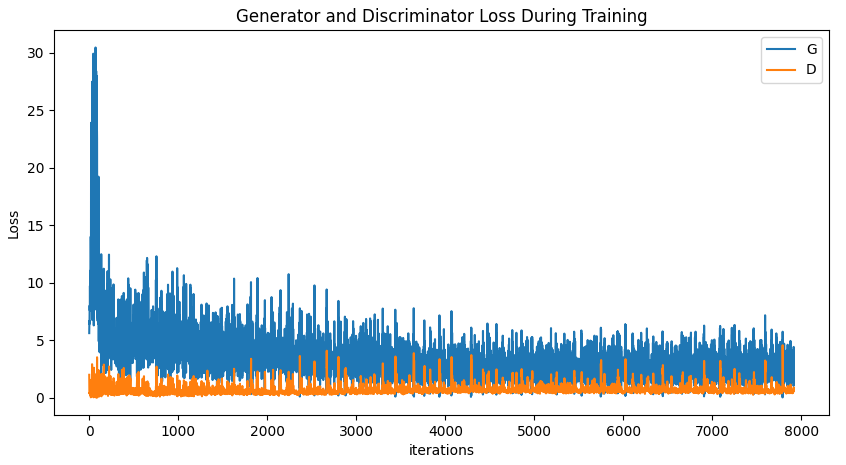
최종적으로 1600여 데이터를 5번의 epoch로 학습시켰을 때, Real Image로 부터 얻어진 Fake Image는 다음과 같이 나온다고 한다.

이제 DCGAN구현을 위한 대략적인 공부는 마친 것 같다. 다음 글에서부터는 MNIST데이터를 가지고 DCGAN을 구현해보고 학습시켜보도록 하자.
Next Article: DCGAN - (4) Implementation of Network for Generator