Previous Article: VAE - (1) Auto-Encoding Variational Bayes
다른 Auto Encoder와 마찬가지로 VAE도 여러 가지 Architecture로 구현할 수 있을 것이다. 다만, Fully Connected Layer로만 구성된 모델은 Image 데이터의 크기가 커질수록 성능에 한계가 있기 때문에 Convolutional Layer로 VAE를 구성하는 것이 일반적이다.
I. Encoder
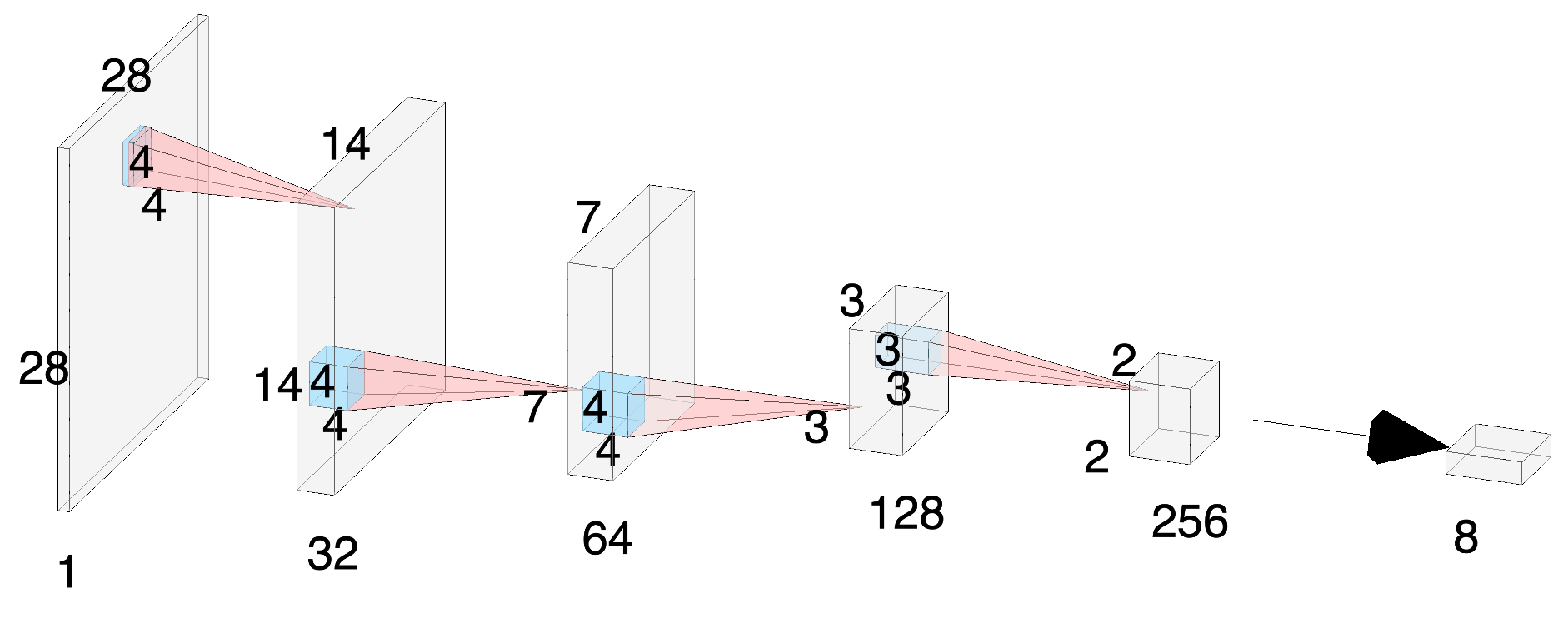
먼저, Encoder의 구조는 위와 같다. 주어진 이미지가 네 개의 Convolutional layer를 거쳐서 두 개의 8차원 벡터로 mapping 된다. (그림에는 하나의 8차원 벡터만 표현되었다.) 각각은 평균과 분산의 log 값에 해당한다. 이후에 각 평균과 분산을 parameter로 가지는 8개의 정규분포에서 sampling 하는 reparametrication 과정을 통해 우리가 원하는 8차원의 latent vector를 얻는다.
II. Decoder
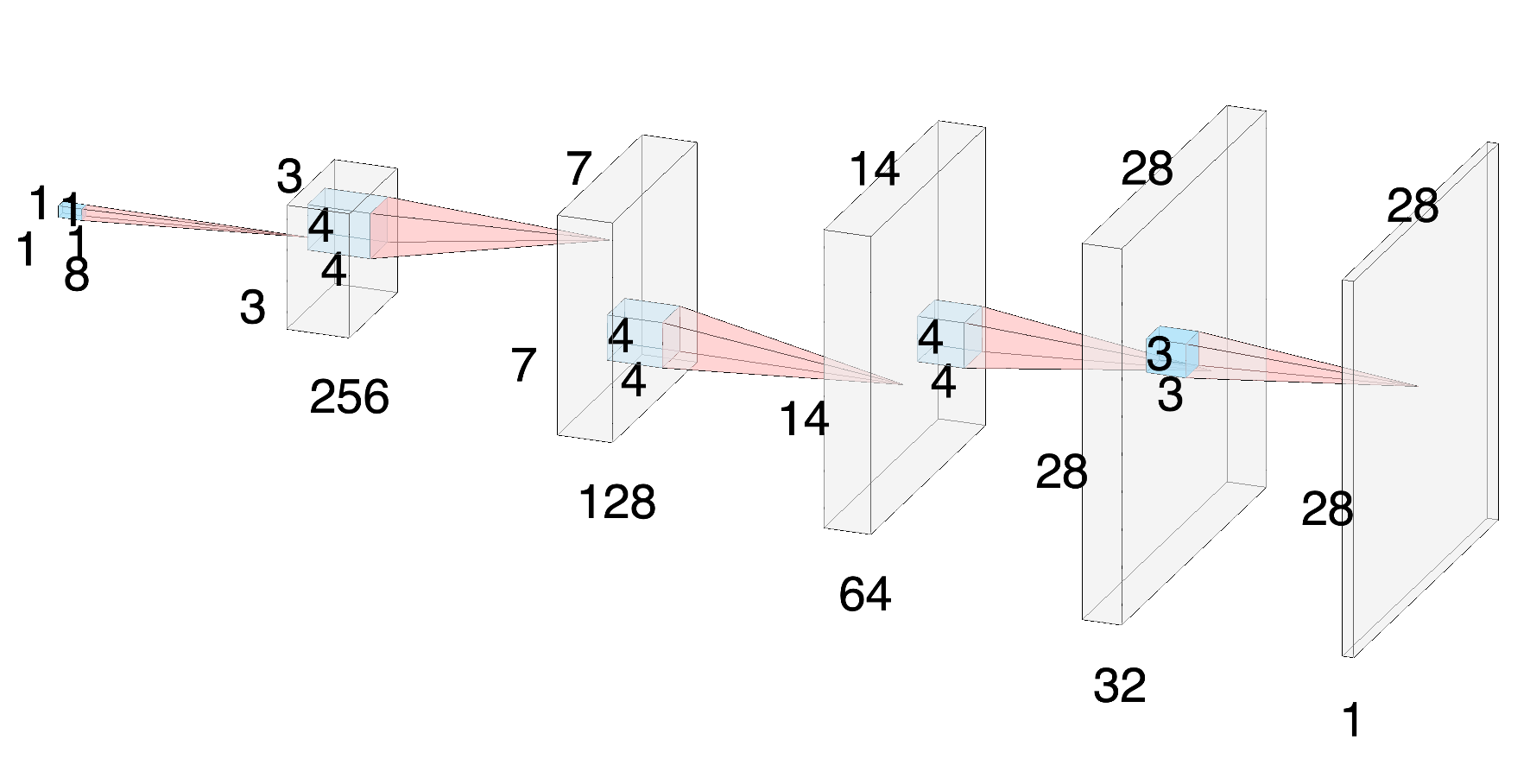
Decoder의 구조는 위와 같이 Encoder의 역순이라고 보면 된다. 점차 height과 width를 늘려 나가는 과정이므로 네 개의 Convolutional Transpose layer를 사용한다. 이후에는 Convolutional layer를 통해 3-channel의 image를 reconstruction 한다.
VAE의 Architecture가 앞서 다룬 DCGAN이나 다른 Auto Encoder 들과 다른 점은 Batch Normalization layer가 없다는 것이다. tensorflow tutorial에 따르면 reparametrication 과정에 따른 무작위성이 이미 존재하기에 여기에 Batch Normalization layer가 추가될 경우 오히려 모델의 정확성이 떨어진다고 언급되어 있다. 실제로 Batch Normalization layer를 넣어서 학습시켜보면 결과물이 뿌옇게 나오는 것을 알 수 있었다. 따라서 VAE에서는 Convolutional layer와 ReLU만을 사용한다.
또한, input image와 reconstructed image의 오차인 loss값을 계산할 때는 decoder로부터 나온 결과에 추가적으로 sigmoid function을 적용한 값을 사용한다. 즉, activation layer가 decoder에는 없고 별도로 sigmoid를 적용하는 것이다. 우리가 결과를 확인할 때 살펴보는 reconstructed image 역시 sigmoid가 적용된 image에 해당한다.
다음 글에서는 pytorch를 통해 학습된 VAE의 결과물들을 살펴보고 이를 해석해보도록 하자.